山西大學(xué)學(xué)報·自然科學(xué)版雜志投稿格式參考范文:基于法條檢索的生成式法律問答研究
時間:
0 引言
法律問答的目標(biāo)是為用戶提供高質(zhì)量、高可靠的法律咨詢,是自然語言處理技術(shù)在司法領(lǐng)域的重要應(yīng)用。智能的法律問答可以幫助律師和法官等司法專業(yè)人士快速地獲取法律知識和信息,也可以為普通民眾提供便利的法律服務(wù)。在社會對法律咨詢服務(wù)的需求日益增加的當(dāng)下,智能法律問答系統(tǒng)能夠發(fā)揮出越來越大的作用,解決法律資源稀缺的問題。
傳統(tǒng)的問答方法以檢索式為主,通過根據(jù)問題計算出的答案得分,來從答案庫中篩選出能夠回答問題的答案。檢索式的問答依賴于龐大的答案庫,沒有產(chǎn)生新答案的能力。一方面,盡管找到的答案包含正確的信息,但答案可能并不能與問題的重點匹配。另一方面,有的答案要求額外的推理與對來自用戶的知識的整合,單純的檢索無法解決這一問題。因此,檢索式的系統(tǒng)并不具備一個直接與用戶交互的問答系統(tǒng)所應(yīng)有的基本特性。
為了解決檢索式中的問題,生成式的方法被廣泛應(yīng)用在了自動問答任務(wù)中。該類方法使用 T5 等生成式模型,在閉卷或參考輔助信息的情況下生成回復(fù)。相較檢索式的方法,生成式的方法靈活很多,盡可能降低了答案庫對回答的影響。盡管如此,生成式的模型可控性較差,且存在幻覺問題。在對可靠性要求較高,需求專業(yè)知識的法律領(lǐng)域,模型更難以生成令人滿意的答復(fù)。
目前,主流的法律問答數(shù)據(jù)集包括選擇題形式的司法考試數(shù)據(jù)集 JEC-QA(Judicial Examination of China Question Answering)、抽取式的法律閱讀理解數(shù)據(jù)集 CJRC(Chinese Judicial Reading Comprehension)與檢索和生成相結(jié)合的司法摘要數(shù)據(jù)集。與開放領(lǐng)域相比,法律問答研究的發(fā)展較為滯后。一方面,現(xiàn)有的法律問答數(shù)據(jù)集與實際的用戶需求相差較大。在現(xiàn)實場景下,用戶的輸入往往只有問題。而用戶期望獲得的,是自然語言形式的流暢回復(fù)。另一方面,主流的法律問答數(shù)據(jù)集缺乏法律知識的指導(dǎo)。在高度專業(yè)化的法律領(lǐng)域,法規(guī)法條是提高模型生成質(zhì)量,監(jiān)督模型生成準(zhǔn)確可靠回復(fù)的有力工具。而現(xiàn)有的數(shù)據(jù)集往往缺乏對問題、答案與法條之間的對應(yīng)關(guān)系的標(biāo)注。此外,由于法律數(shù)據(jù)集的構(gòu)建依賴于法律專家的人工標(biāo)注,高質(zhì)量的中文法律問答數(shù)據(jù)集較為稀缺。
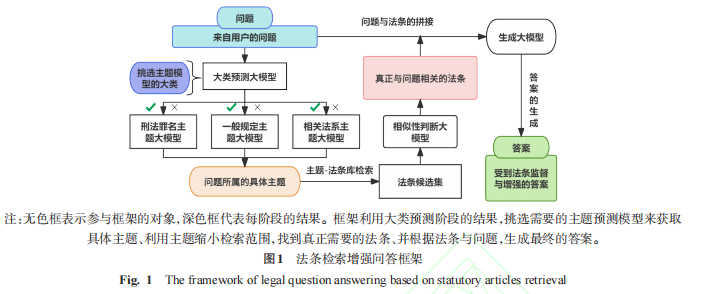
為了解決這些問題,本文提出了基于刑法法條庫的細(xì)粒度中文法律問答數(shù)據(jù)集 FCL-QA(Fine-Grained Criminal Law Question Answering)。該數(shù)據(jù)集包含一萬條收集自中文互聯(lián)網(wǎng)上法律咨詢平臺的問答數(shù)據(jù)。在數(shù)據(jù)集中,根據(jù)分類維度的不同,法條與其對應(yīng)的主題被分為刑法罪名、一般規(guī)定、相關(guān)法系三大類,三大類主題下包含細(xì)致到某一條具體罪名或某一類具體行為的子類。對每條數(shù)據(jù)的標(biāo)注包括兩部分,分別是該數(shù)據(jù)在上述兩個層面上的分類與從法條庫檢索出的、對回答問題有幫助的法條。數(shù)據(jù)的標(biāo)注流程以法條庫為核心展開,以大模型投票與人工校對相結(jié)合的半自動化形式進行,盡可能地緩解了數(shù)據(jù)標(biāo)注的壓力。基于該數(shù)據(jù)集,本文提出了基于大語言模型的法條檢索增強問答框架 SaRAF(Statutory Articles Retrieval Augmented Question Answering Framework),整體流程包括主題預(yù)測、法條檢索、答案生成三部分。
本文的主要貢獻如下:
提出了基于刑法法條庫的法律問答數(shù)據(jù)集 FCL-QA,該數(shù)據(jù)集收集自真實問答平臺,與實際的法律咨詢形式更加接近,能夠反映法律問答實際的需求;
提出了一種半自動化的數(shù)據(jù)標(biāo)注流程,能夠緩解數(shù)據(jù)標(biāo)注的壓力,低成本地擴大數(shù)據(jù)集的規(guī)模;
針對法律問答任務(wù),提出了一種基于大語言模型的法律問答框架 SaRAF。該框架將法律問答所需要的能力拆分成分類、檢索與生成三部分,通過將法條知識與模型經(jīng)驗相結(jié)合來提升模型生成回復(fù)的質(zhì)量;
在 FCL-QA 數(shù)據(jù)集上使用 SaRAF 框架進行了評測,結(jié)果證明,SaRAF 框架可以檢索出用于輔助答案生成的優(yōu)質(zhì)法條。與檢索增強生成(RAG)和不帶任何法條相比,模型在 ROUGE-L F1 指標(biāo)上可提高 11.17 和 4.63 個百分點,在 BLEU-4 指標(biāo)上可提高 13.40 和 5.79 個百分點,在 BERTScore 指標(biāo)上可提高 5.75 和 2.00 個百分點。
1 相關(guān)工作
1.1 法律問答數(shù)據(jù)集
法律問答的發(fā)展離不開優(yōu)質(zhì)數(shù)據(jù)集的創(chuàng)建,按照任務(wù)類型,法律問答數(shù)據(jù)集可以分為:分類式、抽取式、檢索式與文本生成式。其中生成式問答更符合實際問答系統(tǒng)的需求,因此成為研究的熱點。
Zhong 等提出了 JEC-QA,是目前最大的中文法律問答數(shù)據(jù)集,其中的數(shù)據(jù)來自于中國國家司法考試。考慮到回答問題注重的方面,JEC-QA 中的數(shù)據(jù)被分為知識驅(qū)動與案件驅(qū)動兩種類型。JEC-QA 提供了包含需要法律知識與法條的數(shù)據(jù)庫,但并沒有提供問題與法條之間的對應(yīng)關(guān)系。Duan 等通過抽取裁判文書中的事實描述內(nèi)容,構(gòu)建了中文法律閱讀理解數(shù)據(jù)集 CJRC,填補了法律領(lǐng)域閱讀理解研究的空白。該數(shù)據(jù)集的問題由標(biāo)注者以轉(zhuǎn)述的形式給出,涉及種類豐富。2021 年,中國法律智能技術(shù)評測司法摘要賽道提供了涉法輿情摘要數(shù)據(jù)集。該數(shù)據(jù)集通過融合多來源的答案數(shù)據(jù)與對多文檔信息進行摘要精簡,大幅度提高了答案的生成質(zhì)量。Louis 等提出了法語法律數(shù)據(jù)集 LleQA,通過專家注釋為每個問題提供相應(yīng)的法律條款。
1.2 問答模型
在問答領(lǐng)域,深度學(xué)習(xí)的發(fā)展使得生成式的問答成為了可能,Tan 等提出了 S-Net 模型,采用抽取與生成相結(jié)合的范式,使用 Seq2Seq 模型進行答案生成。預(yù)訓(xùn)練語言模型的出現(xiàn)為問答系統(tǒng)的發(fā)展帶來了飛躍式的進步,Karpukhin 等提出了 DPR 模型,通過基于 BERT 模型微調(diào)來完成檢索任務(wù),取得了遠超 BM25 算法的效果。Garg 等提出了 TANDA 模型,通過對預(yù)訓(xùn)練模型進行兩次微調(diào)來提高模型的性能與魯棒性。Roberts 等以閉卷的形式微調(diào) T5 模型,直接輸入問題并獲取對應(yīng)的答案。Hsu 等提出了 GenQA 模型,在 T5 模型的基礎(chǔ)上通過綜合利用問題中信息與候選答案信息生成答案。
在法律問答領(lǐng)域,Wang 等提出了 IflyLegal 系統(tǒng),通過 biRNN 和 CNN 實現(xiàn)用戶意圖的判斷,并通過匹配模型最終從答案庫中檢索出答案。Hoppe 等提出了在文檔檢索的基礎(chǔ)上,使用 BERT 與 BM25 構(gòu)建的德語的法律問答系統(tǒng)。Kien 等基于越南語提出了一種法律文本匹配模型,目的在于找到能夠?qū)卮饐栴}有幫助的法律文章。Louis 等通過檢索增強的框架,構(gòu)建了端到端的基于大語言模型的法律問答系統(tǒng)。
1.3 大語言模型
在生成式任務(wù)中,大模型展示出了卓越的性能,其代表性的工作是 Touvron 等提出的 LlaMA 模型。LlaMA 模型使用 Transformer 架構(gòu),預(yù)測給定單詞或 token 作為下一個單詞或 token 的概率。通過在 1.4T 個 token 上進行訓(xùn)練,LlaMA 模型取得了強大的性能,在常識推理、閉卷問答、閱讀理解、數(shù)學(xué)推理、代碼生成與大規(guī)模語言任務(wù)理解中都取得了優(yōu)秀的成果。
在 LlaMA 被提出后,許多工作都在 LlaMA 框架的基礎(chǔ)上進行,大量開源的大語言模型被公布。Taori 等提出了 Alpaca 模型,在 LlaMA 模型的基礎(chǔ)上使用指令數(shù)據(jù)進行了進一步的微調(diào),取得了媲美 GPT3.5 的水平。Chiang 等提出了 Vicuna 模型,通過收集 ShareGPT 網(wǎng)站上的數(shù)據(jù)來進行指令微調(diào),在低成本的情況下達到了接近 GPT 的能力。Bai 等提出了 Qwen 模型,通過使用高達 3 萬億個 token 的數(shù)據(jù)進行預(yù)訓(xùn)練,為模型提供了可靠的知識源。在 LlaMA 的框架外,Du 等提出了 ChatGLM 模型,針對中文問答和對話進行了專門的優(yōu)化,能夠生成相當(dāng)符合人類偏好的回答。
2 方法
本文構(gòu)建了基于刑法法條庫的法律問答數(shù)據(jù)集 FCL-QA,并基于該數(shù)據(jù)集的特點,提出了一種基于法條檢索的法律問答框架 SaRAF。數(shù)據(jù)集的構(gòu)建過程包括數(shù)據(jù)的收集與清洗、法條庫的構(gòu)建、主題標(biāo)注三個階段。根據(jù)數(shù)據(jù)集的特點,問答流程同樣被劃分為主題預(yù)測、法條檢索與答案生成三部分。
2.1 數(shù)據(jù)集的構(gòu)建
在數(shù)據(jù)收集與清洗階段,本文從中文互聯(lián)網(wǎng)上爬取了 49060 條附有參考法條的問答對數(shù)據(jù)。本文過濾掉了重復(fù)的問答對,依照 2017 年修正版本的《刑法》與 2018 年修正版本的《刑事訴訟法》,依靠人工對爬取到的法條進行了校對。最終,本文將數(shù)據(jù)限定在了 38251 條,并隨機抽取了其中一萬條數(shù)據(jù)作為第一批次的數(shù)據(jù)進行進一步的處理。
在法條庫的構(gòu)建階段,本文首先將法條在刑法罪名、一般規(guī)定與相關(guān)法系三個大層進行了劃分。刑法罪名分類中的法條涉及到刑法中的某一特定罪名。一般規(guī)定分類包括適用于所有罪名的相關(guān)規(guī)定。相關(guān)法系分類中的法條并不屬于刑事的范疇,但因為與刑事領(lǐng)域相關(guān)常被提及。在每一大類下,本文對主題的粒度進行了擴展。比如對于《刑法》中某一章節(jié)名,本文將其下面的每一條法條作為單獨的類別對待,從中拆分出搶劫罪、盜竊罪等具體的主題。最終,每一法條都被歸入到了大類下的某一具體主題中。
在主題標(biāo)注階段,通過將爬取到的法條與法條庫進行對照,本文能夠得到問題所屬的主題。然而,網(wǎng)絡(luò)上爬取到的法條存在與問題不匹配情況。此外,對于涉及到多種主題的問題,單靠法條所屬的主題不足以涵蓋該問題涉及到的所有情況。為了解決這一問題,本文通過人工的標(biāo)注者對數(shù)據(jù)的主題標(biāo)簽進行修正。本文使用基于大語言模型的投票方法,在降低標(biāo)注成本的前提下盡可能地獲取高質(zhì)量的數(shù)據(jù)。
為了訓(xùn)練標(biāo)注模型,本文首先依靠人工對數(shù)據(jù)集中三千條數(shù)據(jù)涉及到的主題進行了標(biāo)注。在標(biāo)注過程中,標(biāo)注者被要求給出問題所涉及到的所有主題,即使回答問題并不需要該主題下的法條。基于這三千條數(shù)據(jù),本文使用 LoRA 微調(diào)的方法,在 ChatGLM-6B 模型上使用不同的 LoRA 秩、LoRA 縮放因子、學(xué)習(xí)率等超參進行了指令微調(diào),訓(xùn)練出五個不同的主題預(yù)測模型。為了確保生成的主題在規(guī)定的主題集內(nèi),本文使用 text2vec 模型,通過余弦相似度計算找到模型結(jié)果在主題庫內(nèi)對應(yīng)的主題。
對單個主題來說,當(dāng)它的票數(shù)大于等于三時,如果該主題來自互聯(lián)網(wǎng)律師,則表明該主題獲得了大模型的再次確認(rèn),能夠排除法條與問題無關(guān)的情況。如果該主題并非來自于法條,則表明該主題獲取了超過半數(shù)以上的大模型的認(rèn)可,雖然沒有相應(yīng)的法條,但該主題應(yīng)同問題強相關(guān)。因此,本文將票數(shù)大于等于三的主題視為可信。完成主題的獲取后,本文通過人工校對來確保問題、答案與主題之間的關(guān)聯(lián)。
2.2 主題預(yù)測
對于主題預(yù)測部分,本文希望能夠由淺入深,通過兩階段的分類任務(wù)來預(yù)測出問題所屬的正確分類。本文通過對大模型進行指令微調(diào)來訓(xùn)練分類模型。
在大體分類預(yù)測階段,本文根據(jù)法條所屬的大類,按照刑法罪名、一般規(guī)定與相關(guān)法系的順序,為問題分配標(biāo)簽信息。在輸入數(shù)據(jù)的描述部分中,本文對此分類任務(wù)進行了介紹并給出了詳細(xì)的分類定義。為了保證模型生成的結(jié)果與預(yù)期一致,本文還在輸入中給出了生成的樣例,在加深模型對任務(wù)理解的同時,限制輸出為期望的格式。在輸入的最后,本文加入了指令,對模型的輸出進行引導(dǎo)。
在具體主題預(yù)測階段,本文根據(jù)問題所屬大類下的主題標(biāo)簽構(gòu)建了大類對應(yīng)的主題預(yù)測訓(xùn)練集,通過指令微調(diào)訓(xùn)練出每個大類下的主題預(yù)測模型。在預(yù)測時,當(dāng)大類預(yù)測階段的結(jié)果在某一位置上為 “1”,本文便選擇出相對應(yīng)的模型用于主題預(yù)測。通過這一流程,原本的多主題多標(biāo)簽分類任務(wù)被轉(zhuǎn)換為單標(biāo)簽多分類任務(wù),在降低了主題預(yù)測的難度的同時,使得預(yù)測的結(jié)果更加準(zhǔn)確可靠。在該階段中,本文同樣使用 text2vec 模型對不在主題集內(nèi)的主題進行糾正。
2.3 法條檢索
對于法條檢索部分,本文將檢索任務(wù)轉(zhuǎn)換為相關(guān)性判別任務(wù),通過指令微調(diào)引導(dǎo)大模型輸出 “0” 或 “1” 來對問題與法條之間的關(guān)系進行判斷。
為了訓(xùn)練檢索模型,本文利用數(shù)據(jù)集中標(biāo)注好的主題標(biāo)簽與相關(guān)法條,構(gòu)建了相關(guān)性判斷訓(xùn)練集。對于每條與問題相關(guān)的法條,本文將其與問題拼接在一起,構(gòu)成一個正樣本對。根據(jù)主題標(biāo)簽,本文從整體的法條庫中檢索出了問題對應(yīng)的候選法條集合,并使用集合中與問題無關(guān)的法條構(gòu)成負(fù)樣本對。Cai 等的研究表明,處理數(shù)據(jù)集中的不平衡問題對分類模型的正確性和準(zhǔn)確性十分重要。因此,本文在構(gòu)建檢索訓(xùn)練集時對負(fù)樣本的數(shù)目加以限制,保證正負(fù)樣本的數(shù)目能夠保持一致。
在實際的問答場景下,本文根據(jù)主題預(yù)測階段的結(jié)果為問題篩選出候選法條集,并按照指令數(shù)據(jù)的格式拼接問題與法條,輸入給大模型進行判斷。為了防止問題找不到對應(yīng)的法條,本文利用全量的正負(fù)樣本集合,額外訓(xùn)練了 SBERT 模型。SBERT 模型的訓(xùn)練目標(biāo)是,給定問題 q、相關(guān)法條 P 和無關(guān)法條 n,使得 q 和 P 之間的距離盡可能小,q 和 n 之間的距離盡可能大。當(dāng)問題找不到對應(yīng)的法條時,本文通過 SBERT 模型來進行相似度判斷,尋找到候選集合中與問題最匹配的法條。
2.4 答案生成
對于答案生成部分,本文將問題與法條進行了拼接,輸入到大模型中進行答案生成。
在本部分中,本文利用了大模型優(yōu)秀的自然語言生成能力,實現(xiàn)了法條知識與模型經(jīng)驗信息的融合。在訓(xùn)練階段,使用的法條數(shù)據(jù)為經(jīng)過標(biāo)注后的準(zhǔn)確法條。在測試階段,使用的法條數(shù)據(jù)為從法條檢索階段獲得的法條。
3 實驗與分析
3.1 數(shù)據(jù)集
本文主要在構(gòu)建的 FLC-QA 數(shù)據(jù)集上進行實驗。在數(shù)據(jù)集中,每條數(shù)據(jù)包含一對問答對、若干條問題的相關(guān)法條、問題所屬的大類與問題所屬的主題。
本文按 9∶1 的比例,對訓(xùn)練集與驗證集進行劃分。在主題預(yù)測任務(wù)中,訓(xùn)練集通過根據(jù)大類標(biāo)簽對訓(xùn)練集進行歸類獲得。主題預(yù)測、法條檢索任務(wù)的驗證集分別根據(jù)流程中上一步的結(jié)果獲得。不同模型間存在一定的誤差。
3.2 評價指標(biāo)
對于大類預(yù)測任務(wù),使用準(zhǔn)確率(Acc)作為評價指標(biāo)。對于主題預(yù)測任務(wù),使用 Micro-F1 分?jǐn)?shù)(Top_F1)作為評價指標(biāo),通過正確預(yù)測出的主題數(shù)、模型預(yù)測出來的主題數(shù)與實際預(yù)期的主題數(shù)計算精確率 P、召回率 R,進而得出 Micro-F1 分?jǐn)?shù)。
對于法條檢索任務(wù),將其轉(zhuǎn)換為相關(guān)性判斷的二分類任務(wù),采用 Micro-F1 分?jǐn)?shù)(Re_F1)進行評價,通過模型檢索到的相關(guān)法條數(shù)目、所有法條數(shù)目與問題相關(guān)的法條數(shù)目計算精確率、召回率及 F1 分?jǐn)?shù)。
對于答案生成任務(wù),采用 ROUGE-L 和 BLEU-4,根據(jù)重疊詞語的相似度度量評估生成質(zhì)量,采用 BERTScore,根據(jù)語義相似度評估生成質(zhì)量。ROUGE-L 使用機器輸出與參考答案的最長公共子序列計算,BLEU 通過計算單詞級別的準(zhǔn)確性衡量句子流暢性,BERTScore 將問題和回答編碼為 BERT 向量,計算生成文本與參考文本的余弦相似度得到精確率、召回率并計算 F1 分?jǐn)?shù),本文使用 chinese-roberta-large 模型獲取 BERT 向量表示。
3.3 基線模型
實驗采用 10 個模型作為數(shù)據(jù)集上的基線模型,分別為:ChatGLM3-6B、LLaMA3-8B、Qwen-7B、LegalEagle、LaWGPT、太令、GPT-3.5、T5 PEGASUS、T5 Copy、SBERT。
3.4 實驗設(shè)置
所有實驗基于深度學(xué)習(xí)框架 PyTorch,在 Linux 平臺上使用一張 RTX4090 顯卡訓(xùn)練。在框架上使用不同大模型,基于 Firefly 項目進行 QLoRA 指令微調(diào)完成各項任務(wù)流程。除大模型外,在法條檢索階段訓(xùn)練 SBERT 模型、在答案生成階段訓(xùn)練 T5 模型作為對照。在數(shù)據(jù)集上以
2×10 −4的學(xué)習(xí)率微調(diào) 2 個迭代輪次,訓(xùn)練批大小設(shè)置為 4,lora_rank、lora_alpha 等參數(shù)均設(shè)置為 16,使用訓(xùn)練中最后保存的 LoRA 權(quán)重用于驗證集上的測試。
3.5 實驗結(jié)果
不同模型在 SaRAF 框架中的大類預(yù)測與主題預(yù)測階段實驗結(jié)果顯示,兩階段預(yù)測后所有模型在主題預(yù)測階段表現(xiàn)均提升,ChatGLM3-6B 模型 F1 指標(biāo)提高 14.33 個百分點。單階段預(yù)測時 LegalEagle 模型成績最好,兩階段預(yù)測后 ChatGLM3-6B 模型反超。
在法條檢索階段,大部分模型使用 SBERT 模型檢索時精確率優(yōu)于 SaRAF 框架,但在召回率上,除 LawGPT 模型外,SaRAF 框架結(jié)果更優(yōu) ,更符合檢索增強問答任務(wù)需求。
答案生成階段,使用 SaRAF 進行檢索增強的效果全面優(yōu)于使用 RAG,在 ROUGE-L F1、BLEU 和 BERTScore 指標(biāo)上均存在差距。預(yù)訓(xùn)練 T5 模型即使使用準(zhǔn)確法條表現(xiàn)仍不如 SaRAF 框架下的大模型,GPT-3.5 未微調(diào)也不如經(jīng)過指令微調(diào)的基座大模型。
3.6 檢索指標(biāo)分析
構(gòu)造正負(fù)樣本平衡訓(xùn)練集可防止過多負(fù)樣本干擾模型對正樣本的識別能力。實驗表明,使用非平衡訓(xùn)練集訓(xùn)練后,模型檢索出的正例和真正例數(shù)目減少,召回率下降,精確率提高。將非平衡訓(xùn)練后檢索到的法條用于答案生成,ROUGE-L F1 指標(biāo)下降。說明在檢索增強場景下,召回率與答案質(zhì)量正向關(guān)聯(lián),SaRAF 框架是更合適的檢索器。
3.7 消融實驗
消融掉法條檢索過程的實驗顯示,沒有法條輔助生成時,模型生成結(jié)果劣于 SaRAF 框架下的生成結(jié)果;使用正確法條后,模型生成質(zhì)量提升。說明 SaRAF 框架中檢索獲取的法條有效,對答案生成有積極影響,該框架仍有提升空間。
3.8 案例分析
不使用多等級主題分類檢索限定范圍,直接利用向量相似度檢索會導(dǎo)致檢索出大量無關(guān)法條,影響答案生成質(zhì)量。使用 SaRAF 框架也可能出現(xiàn)錯誤,如模型無法找到關(guān)鍵法條,導(dǎo)致答案不準(zhǔn)確。
為全面評估生成的答案,從驗證集中選取 100 條數(shù)據(jù),使用 ChatGLM3-6B 作為基座模型,獲取不同框架下的答案并邀請人工標(biāo)注者判斷是否存在幻覺。結(jié)果表明模型生成的答案存在幻覺問題,SaRAF 框架下答案錯誤類型的幻覺率最高,RAG 框架幻覺率在各方面最高,法條能降低幻覺率。
3.9 幻覺分析
法條在答案生成過程中起到監(jiān)督與引導(dǎo)作用,能應(yīng)對大模型幻覺問題。通過利用法條對答案進行修正與參考,可提高答案的真實性與質(zhì)量。
4 總結(jié)
針對生成式的法律問答任務(wù),本文提出細(xì)粒度的刑法問答數(shù)據(jù)集 FCL-QA,收集自然語言形式的刑法領(lǐng)域問答對,整理相關(guān)法條,建立問答對與法條間的檢索路徑。基于 FCL-QA 提出法條檢索增強框架 SaRAF,通過多級分類獲取問題主題輔助法條檢索,結(jié)合大模型經(jīng)驗與法條知識生成高質(zhì)量回復(fù),實驗證明了 SaRAF 框架的可靠性。
未來將進一步擴充數(shù)據(jù)集,探索提高大模型問答系統(tǒng)性能的方法。
李明達;邸洪波;孫媛媛;王艷華;楊志豪;林鴻飛,大連理工大學(xué)計算機科學(xué)與技術(shù)學(xué)院;大連市公安局網(wǎng)安支隊;中國人民解放軍空軍通信士官學(xué)校,202501
